We’re excited to be teaming up with Hired to bring you career insights about diversity, inclusion, and the job market.
Writing clear, understandable code for complex systems can be a challenge for software developers or students learning to code. This can be intimidating when learning to code, but as an ally in the programming community, we’ll walk you through a way to make your coding more understandable. In this post, we’ll explore the concept of self-documenting code as a technique for writing clearer code.
What is self-documenting code?
Self-documenting code is code that doesn’t require code comments for a human to understand its naming conventions and what it is doing. It utilizes descriptive method and variable names that resemble human speech. You may understand this concept even if you’ve not heard the term before. Other synonymous names include “human-readable code” and “self-describing code.”
Why is it useful?
Writing understandable code is hard:
- People think and solve problems in different ways
- Systems are complex and sometimes require workarounds or unintuitive solutions
- Not everyone contributing to a codebase has the same context about the entire system
- Comments and documentation can become outdated
Self-documenting code aims to solve these issues by encouraging code that clearly states its intent in common language.
Tic-tac-toe: A self-documenting code example
The good news is that writing self-documenting code can be very intuitive, because it mimics the way that we naturally think. To give an example of how we can refactor code to be more self-documenting, let’s use the childhood game of tic-tac-toe.
Intro
For those unfamiliar with the game, it works as follows: There is a 3 x 3 grid and two players, ‘X’ and ‘O’. The two players take turns marking spots on the grid. The first player to mark three spots in a straight line wins the game.
I’ve written a preliminary implementation below. The code is pretty short, and the game is fairly simple. However, upon first glance, you might wonder, “What the heck is happening here?” Even for such a straightforward program, the code takes a moment to grok.
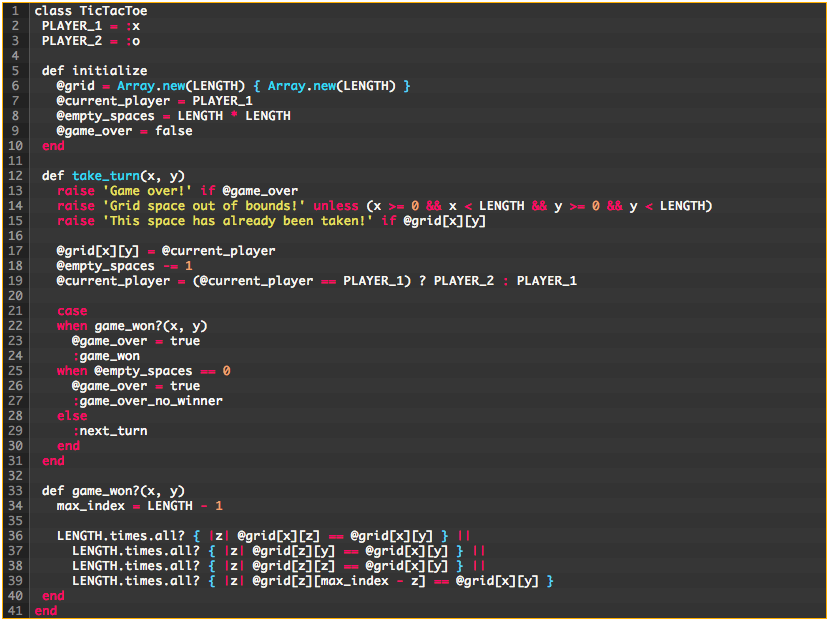
Refactoring strategy
So how can we make this code easier to read, understand, and maintain? I’ll use the following refactoring technique:
- Identify functionally significant, independent pieces of code
- Extract these pieces of code into methods with human-readable names
- Repeat until all code is sufficiently human-readable
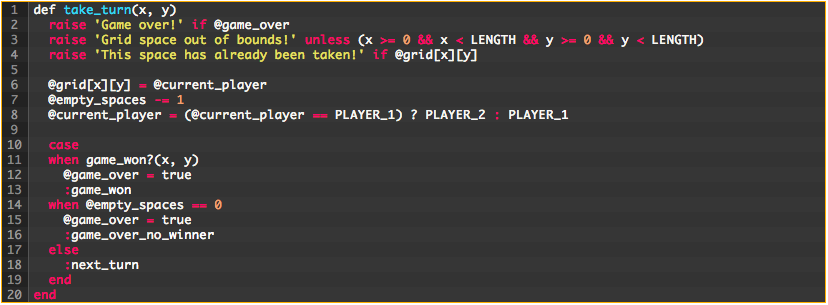
Let’s start here with the take_turn method:
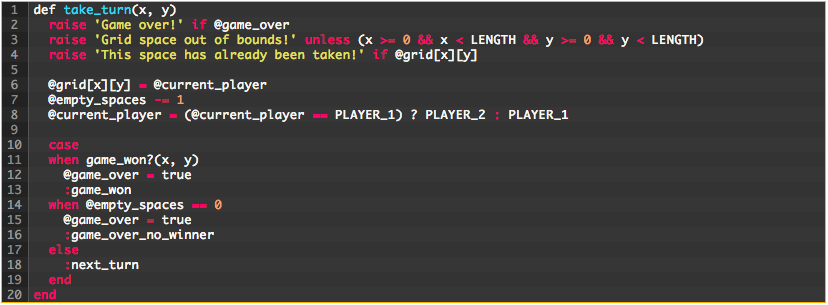
Specifically, let’s take a look at the first three lines of code above. This chunk of code appears to deal with error checking. Great! Let’s extract that out into its own method and name it something descriptive:

Looking better already!
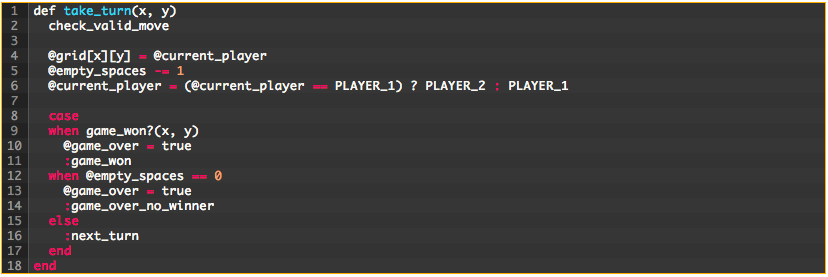
But we’re not quite done with the error checking code yet. We can make this even more readable. Let’s try some more refactoring:

With a couple simple extractions, the error checking code is now even more readable:

There isn’t much more code that can be pulled out of here, so let’s return to take_turn:

The next chunk of code has a lot going on. What exactly is it doing? It appears to be marking the spot with the current player’s symbol, decrementing the number of empty spaces, and swapping players in preparation for the next turn. So, let’s update the code to say just that:
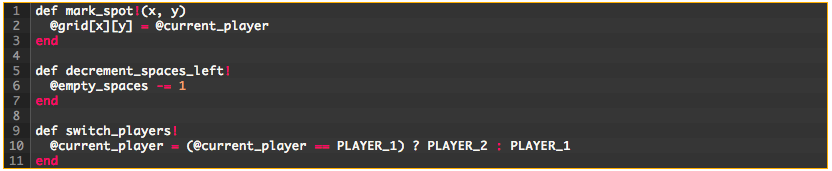
Now:

Let’s tackle the final chunk of code:

For fun, let’s also go ahead and refactor the game_won? method:
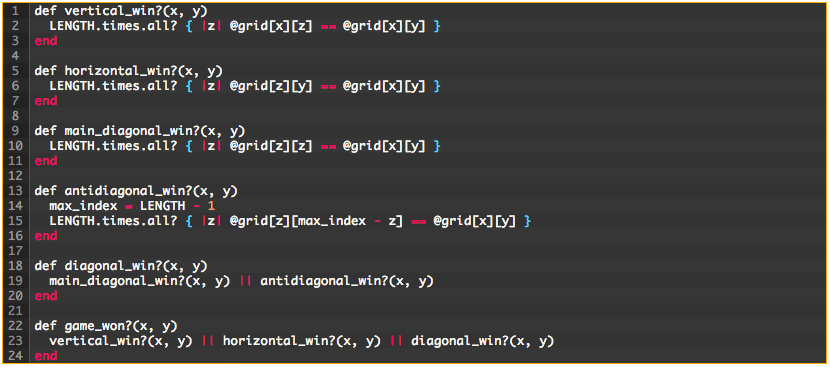
Before:
After:

Not bad! The new code is much easier to read and understand. If we want to know the specifics of what the methods are doing, we can visit the definitions. We now also have a better idea of what the developer intended for the methods to do, which makes it easier to spot bugs or make modifications.
An added bonus: better tests
We’ve now seen how self-documenting code can make programs easier to read and understand. However, self-documenting code can also make programs easier to test. Self-documenting code encourages developers to write many small, single-function methods, rather than larger, multi-functional monolithic methods. In addition to being easier to understand, these smaller methods are also easier to test. This is because the input and output spaces for these smaller methods is more constrained than in the larger, more complex methods.
As an example, try to imagine all of the tests that you would need to write to comprehensively test take_turn. It’s pretty difficult to enumerate all of the possible input and ouptut conditions that you’d need to test for to ensure full coverage. Now, for comparison, imagine the tests that you’d need to write to fully test mark_spot! or switch_players!. Much easier, right? Since the purpose of each of these methods is very narrowly defined, the input and output spaces are also much simpler to enumerate. This pattern results not only in better test coverage, but also clearer tests that serve as additional documentation regarding the intent of the code.
Conclusion
Writing understandable code is hard. Even the smallest programs, as demonstrated by the original tic-tac-toe code above, can be difficult to follow. This, of course, does not bode well for the building of large, complex, multi-contributor systems. However, using the principles of self-documenting code can help! Even if you already have code that isn’t self-documenting, the good news is that it is relatively painless to transform existing code into self-documenting code. This can be done by iteratively extracting portions of code into single-use and single-line methods with descriptive names. In this way, even the most complex code can be quickly converted into self-documenting code that is clearer and easier to understand.
If you’re ready to start your coding journey, check out the courses we offer in our diverse and welcoming learning environment here at Hackbright Academy.
 About the author: Leah Dorner is a software developer on Hired’s Candidate Experience team. Prior to Hired, Leah worked as a software developer on Twitter’s Product Security team. When not writing code, Leah enjoys eating ice cream, wearing onesies, and spending time outdoors (perhaps even all at the same time). Leah finds it odd writing about herself in the third person.
About the author: Leah Dorner is a software developer on Hired’s Candidate Experience team. Prior to Hired, Leah worked as a software developer on Twitter’s Product Security team. When not writing code, Leah enjoys eating ice cream, wearing onesies, and spending time outdoors (perhaps even all at the same time). Leah finds it odd writing about herself in the third person.
This piece was originally published on Hired’s Tech Careers Blog. Hired is a marketplace that matches tech talent with the world’s most innovative companies. Learn more here.
Recommended Reading
The 10 Best Software Engineering Blogs